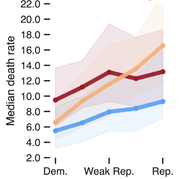
The COVID-19 pandemic has had intense, heterogeneous impacts on different communities and geographies in the United States. We explore county-level associations between COVID-19 attributed deaths and social, demographic, vulnerability, and political variables to develop a better understanding of the evolving roles these variables have played in relation to mortality. We focus on the role of political variables, as captured by support for either the Republican or Democratic presidential candidates in the 2020 elections and the stringency of state-wide governor mandates, during three non-overlapping time periods between February 2020 and February 2021. We find that during the first three months of the pandemic, Democratic-leaning and internationally-connected urban counties were affected. During subsequent months (between May and September 2020), Republican counties with high percentages of Hispanic and Black populations were most hardly hit. In the third time period –between October 2020 and February 2021– we find that Republican-leaning counties with loose mask mandates experienced up to 3 times higher death rates than Democratic-leaning counties, even after controlling for multiple social vulnerability factors. Some of these deaths could perhaps have been avoided given that the effectiveness of non-pharmaceutical interventions in preventing uncontrolled disease transmission, such as social distancing and wearing masks indoors, had been well-established at this point in time.
COVID-19 fundamentally changed the world in a matter of months. To understand how it was impacting life in the United States, we fielded a non-probability survey in all 50 states concerning people's attitudes, beliefs, and behaviors, designed to be representative at the state level. Here, we evaluate the generalizability of this study by assessing the representativeness and convergent validity of our estimates. First, we evaluate the representativeness of the sample by comparing it to baseline estimates and auditing the size of the weights we use to reduce bias. We find our sample is diverse and most weights are below levels of concern with the exception of Hispanic respondents. Second, we assess the convergent validity of our survey by evaluating how our estimates of attitudes, behaviors, and opinions compare to estimates from other surveys and administrative data. Third, we perform a direct comparison of our results to the Kaiser Family Foundation’s probability-based COVID-19 Vaccine Monitor. Overall, our estimates deviate from others by 1%-7% with the larger differences stemming from states with small populations and few other data sources and estimates from items with differing question wording or response choices. Here, we put forward a standard for evaluating the representativeness of surveys, non-probability or otherwise.
Prevalance and Correlates of Long COVID Symptoms among US Adults Roy H. Perlis, Mauricio Santillana, Katherine Ognyanova, Alauna Safarpour, Kristin Lunz Trujillo, Matthew D. Simonson, Jon Green, Alexi Quintana, James Druckman, Matthew A. Baum, David Lazer JAMA Netw Open. 2022;5(10):e2238804.
Abstract
Key Points Question How common are COVID-19 symptoms lasting longer than 2 months, also known as long COVID, among adults in the United States, and which adults are most likely to experience long COVID?
Findings In this cross-sectional study of more than 16 000 individuals, 15% of US adults with a prior positive COVID-19 test reported current symptoms of long COVID. Those who completed a primary vaccination series prior to infection were less likely to report long COVID symptoms.
Meaning This study suggests that long COVID is prevalent and that the risk varies among individual subgroups in the United States; vaccination may reduce this risk.
Abstract Importance Persistence of COVID-19 symptoms beyond 2 months, or long COVID, is increasingly recognized as a common sequela of acute infection.
Objectives To estimate the prevalence of and sociodemographic factors associated with long COVID and to identify whether the predominant variant at the time of infection and prior vaccination status are associated with differential risk.
Design, Setting, and Participants This cross-sectional study comprised 8 waves of a nonprobability internet survey conducted between February 5, 2021, and July 6, 2022, among individuals aged 18 years or older, inclusive of all 50 states and the District of Columbia.
Main Outcomes and Measures Long COVID, defined as reporting continued COVID-19 symptoms beyond 2 months after the initial month of symptoms, among individuals with self-reported positive results of a polymerase chain reaction test or antigen test.
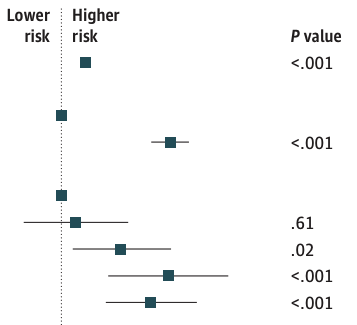
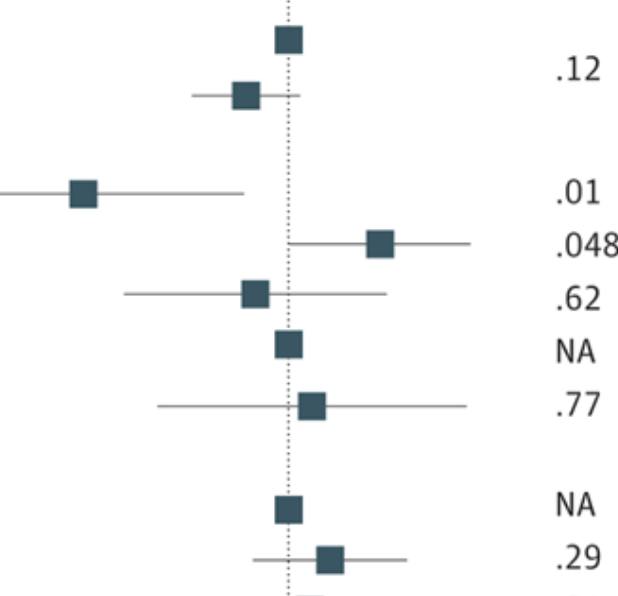
Results The 16 091 survey respondents reporting test-confirmed COVID-19 illness at least 2 months prior had a mean age of 40.5 (15.2) years; 10 075 (62.6%) were women, and 6016 (37.4%) were men; 817 (5.1%) were Asian, 1826 (11.3%) were Black, 1546 (9.6%) were Hispanic, and 11 425 (71.0%) were White. From this cohort, 2359 individuals (14.7%) reported continued COVID-19 symptoms more than 2 months after acute illness. Reweighted to reflect national sociodemographic distributions, these individuals represented 13.9% of those who had tested positive for COVID-19, or 1.7% of US adults. In logistic regression models, older age per decade above 40 years (adjusted odds ratio [OR], 1.15; 95% CI, 1.12-1.19) and female gender (adjusted OR, 1.91; 95% CI, 1.73-2.13) were associated with greater risk of persistence of long COVID; individuals with a graduate education vs high school or less (adjusted OR, 0.67; 95% CI, 0.56-0.79) and urban vs rural residence (adjusted OR, 0.74; 95% CI, 0.64-0.86) were less likely to report persistence of long COVID. Compared with ancestral COVID-19, infection during periods when the Epsilon variant (OR, 0.81; 95% CI, 0.69-0.95) or the Omicron variant (OR, 0.77; 95% CI, 0.64-0.92) predominated in the US was associated with diminished likelihood of long COVID. Completion of the primary vaccine series prior to acute illness was associated with diminished risk for long COVID (OR, 0.72; 95% CI, 0.60-0.86).
Conclusions and Relevance This study suggests that long COVID is prevalent and associated with female gender and older age, while risk may be diminished by completion of primary vaccination series prior to infection.
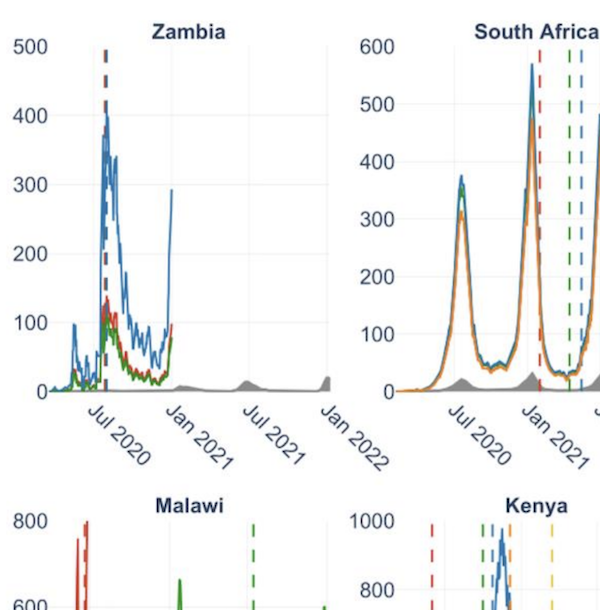
Background The COVID-19 pandemic has had a devastating impact on global health, the magnitude of which appears to differ intercontinentally: for example, reports suggest 271,900 per million people have been infected in Europe versus 8,800 per million people in Africa. While Africa is the second largest continent by population, its reported COVID-19 cases comprise <3% of global cases. Although social, environmental, and environmental explanations have been proposed to clarify this discrepancy, systematic infection underascertainment may be equally responsible. Methods We seek to quantify magnitudes of underascertainment in COVID-19’s cumulative incidence in Africa. Using serosurveillance and postmortem surveillance, we constructed multiplicative factors estimating ratios of true infections to reported cases in Africa since March 2020. Results Multiplicative factors derived from serology data (subset of 12 nations) suggested a range of COVID-19 reporting rates, from 1 in 2 infections reported in Cape Verde (July 2020) to 1 in 3,795 infections reported in Malawi (June 2020). A similar set of multiplicative factors for all nations derived from postmortem data points toward the same conclusion: reported COVID-19 cases are unrepresentative of true infections, suggesting a key reason for low case burden in many African nations is significant underdetection and underreporting. Conclusions While estimating COVID-19’s exact burden is challenging, the multiplicative factors we present furnish incidence estimates reflecting likely-to-worst-case ranges of infection. Our results stress the need for expansive surveillance to allocate resources in areas experiencing discrepancies between reported cases, projected infections, and deaths.
Background Assessment of disease severity associated with a novel pathogen or variant provides crucial information needed by public health agencies and governments to develop appropriate responses. The SARS-CoV-2 omicron variant of concern (VOC) spread rapidly through populations worldwide before robust epidemiological and laboratory data were available to investigate its relative severity. Here we develop a set of methods that make use of non-linked, aggregate data to promptly estimate the severity of a novel variant, compare its characteristics with those of previous VOCs, and inform data-driven public health responses. Methods Using daily population-level surveillance data from the National Institute for Communicable Diseases in South Africa (March 2, 2020, to Jan 28, 2022), we determined lag intervals most consistent with time from case ascertainment to hospital admission and within-hospital death through optimisation of the distance correlation coefficient in a time series analysis. We then used these intervals to estimate and compare age-stratified case-hospitalisation and case-fatality ratios across the four epidemic waves that South Africa has faced, each dominated by a different variant. Findings A total of 3 569 621 cases, 494 186 hospitalisations, and 99 954 deaths attributable to COVID-19 were included in the analyses. We found that lag intervals and disease severity were dependent on age and variant. At an aggregate level, fluctuations in cases were generally followed by a similar trend in hospitalisations within 7 days and deaths within 15 days. We noted a marked reduction in disease severity throughout the omicron period relative to previous waves (age-standardised case-fatality ratios were consistently reduced by >50%), most substantial for age strata with individuals 50 years or older.
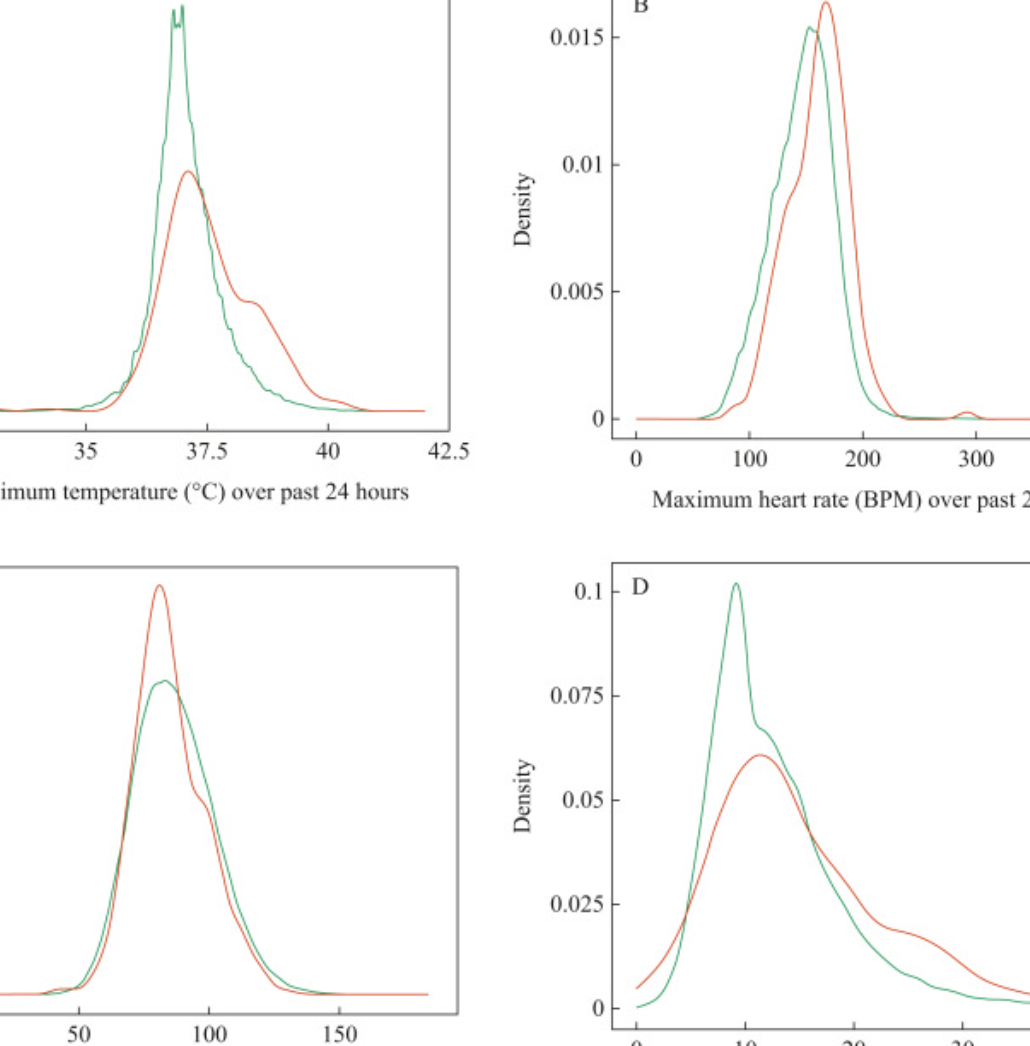
Background While modelling of central-line-associated blood stream infection (CLABSI) risk factors is common, models that predict an impending CLABSI in real time are lacking. Aim To build a prediction model which identifies patients who will develop a CLABSI in the ensuing 24 h. Methods We collected variables potentially related to infection identification in all patients admitted to the cardiac intensive care unit or cardiac ward at Boston Children's Hospital in whom a central venous catheter (CVC) was in place between January 2010 and August 2020, excluding those with a diagnosis of bacterial endocarditis. We created models predicting whether a patient would develop CLABSI in the ensuing 24 h. We assessed model performance based on area under the curve (AUC), sensitivity and false-positive rate (FPR) of models run on an independent testing set (40%). Findings A total of 104,035 patient-days and 139,662 line-days corresponding to 7468 unique patients were included in the analysis. There were 399 positive blood cultures (0.38%), most commonly with Staphylococcus aureus (23% of infections). Major predictors included a prior history of infection, elevated maximum heart rate, elevated maximum temperature, elevated C-reactive protein, exposure to parenteral nutrition and use of alteplase for CVC clearance. The model identified 25% of positive cultures with an FPR of 0.11% (AUC = 0.82). Conclusions A machine-learning model can be used to predict 25% of patients with impending CLABSI with only 1.1/1000 of these predictions being incorrect. Once prospectively validated, this tool may allow for early treatment or prevention.
Patients’ no-shows, scheduled but unattended medical appointments, have a direct negative impact on patients’ health, due to discontinuity of treatment and late presentation to care. They also lead to inefficient use of medical resources in hospitals and clinics. The ability to predict a likely no-show in advance could enable the design and implementation of interventions to reduce the risk of it happening, thus improving patients’ care and clinical resource allocation. In this study, we develop a new interpretable deep learning-based approach for predicting the risk of no-shows at the time when a medical appointment is first scheduled. The retrospective study was conducted in an academic pediatric teaching hospital with a 20% no-show rate. Our approach tackles several challenges in the design of a predictive model by (1) adopting a data imputation method for patients with missing information in their records (77% of the population), (2) exploiting local weather information to improve predictive accuracy, and (3) developing an interpretable approach that explains how a prediction is made for each individual patient. Our proposed neural network-based and logistic regression-based methods outperformed persistence baselines. In an unobserved set of patients, our method correctly identified 83% of no-shows at the time of scheduling and led to a false alert rate less than 17%. Our method is capable of producing meaningful predictions even when some information in a patient’s records is missing. We find that patients’ past no-show record is the strongest predictor. Finally, we discuss several potential interventions to reduce no-shows, such as scheduling appointments of high-risk patients at off-peak times, which can serve as starting point for further studies on no-show interventions.
Near real-time surveillance of the SARS-CoV-2 epidemic with incomplete data Pablo M De Salazar, Fred Lu, James A Hay, Diana Gómez-Barroso, Pablo Fernández-Navarro, Elena V Martínez, Jenaro Astray-Mochales, Rocío Amillategui, Ana García-Fulgueiras, Maria D Chirlaque, Alonso Sánchez-Migallón, Amparo Larrauri, María J Sierra, Marc Lipsitch, Fernando Simón, Mauricio Santillana, Miguel A Hernán PLoS computational biology 18 (3), e100996442022
Abstract
When responding to infectious disease outbreaks, rapid and accurate estimation of the epidemic trajectory is critical. However, two common data collection problems affect the reliability of the epidemiological data in real time: missing information on the time of first symptoms, and retrospective revision of historical information, including right censoring. Here, we propose an approach to construct epidemic curves in near real time that addresses these two challenges by 1) imputation of dates of symptom onset for reported cases using a dynamically-estimated “backward” reporting delay conditional distribution, and 2) adjustment for right censoring using the NobBS software package to nowcast cases by date of symptom onset. This process allows us to obtain an approximation of the time-varying reproduction number (Rt) in real time. We apply this approach to characterize the early SARS-CoV-2 outbreak in two Spanish regions between March and April 2020. We evaluate how these real-time estimates compare with more complete epidemiological data that became available later. We explore the impact of the different assumptions on the estimates, and compare our estimates with those obtained from commonly used surveillance approaches. Our framework can help improve accuracy, quantify uncertainty, and evaluate frequently unstated assumptions when recovering the epidemic curves from limited data obtained from public health systems in other locations.
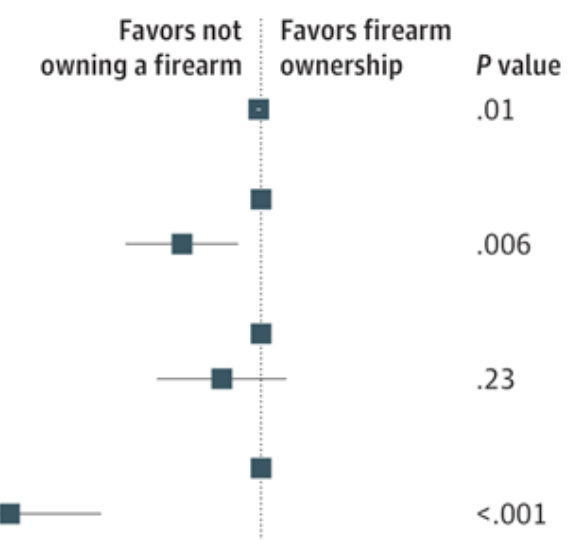
Prevalence of firearm ownership among individuals with major depressive symptoms Roy H Perlis, Matthew D Simonson, Jon Green, Jennifer Lin, Alauna Safarpour, Kristin Lunz Trujillo, Alexi Quintana, Hanyu Chwe, John Della Volpe, Katherine Ognyanova, Mauricio Santillana, James Druckman, David Lazer, Matthew A Baum JAMA network open 5 (3), e223245-e22324512022
Abstract
ImportanceBoth major depression and firearm ownership are associated with an increased risk for death by suicide in the United States, but the extent of overlap among these major risk factors is not well characterized. ObjectiveTo assess the prevalence of current and planned firearm ownership among individuals with depression. Design, Setting, and ParticipantsCross-sectional survey study using data pooled from 2 waves of a 50-state nonprobability internet survey conducted between May and July 7, 2021. Internet survey respondents were 18 years of age or older and were sampled from all 50 US states and the District of Columbia. Main Outcomes and MeasuresSelf-reported firearm ownership; depressive symptoms as measured by the 9-item Patient Health Questionnaire. ResultsOf 24 770 survey respondents (64.6% women and 35.4% men; 5.0% Asian, 10.8% Black, 7.5% Hispanic, and 74.0% White; mean [SD] age 45.8 [17.5]), 6929 (28.0%) reported moderate or greater depressive symptoms; this group had mean (SD) age of 38.18 (15.19) years, 4587 were female (66.2%), and 406 were Asian (5.9%), 725 were Black (10.5%), 652 were Hispanic (6.8%), and 4902 were White (70.7%). Of those with depression, 31.3% reported firearm ownership (n = 2167), of whom 35.9% (n = 777) reported purchasing a firearm within the past year. In regression models, the presence of moderate or greater depressive symptoms was not significantly associated with firearm ownership (adjusted odds ratio [OR], 1.07; 95% CI, 0.98-1.17) but was associated with greater likelihood of a first-time firearm purchase during the COVID-19 pandemic (adjusted OR, 1.77; 95% CI, 1.56-2.02) and greater likelihood of considering a future firearm purchase (adjusted OR, 1.53; 95% CI, 1.23-1.90). Conclusions and RelevanceIn this study, current and planned firearm ownership was common among individuals with major depressive symptoms, suggesting a public health opportunity to address this conjunction of suicide risk factors.
Global modeling of atmospheric chemistry is a great computational challenge because of the cost of integrating the kinetic equations for chemical mechanisms with typically over 100 coupled species. Here we present an adaptive algorithm to ease this computational bottleneck with no significant loss in accuracy and apply it to the GEOS-Chem global 3-D model for tropospheric and stratospheric chemistry (228 species, 724 reactions). Our approach is inspired by unsupervised machine learning clustering techniques and traditional asymptotic analysis ideas. We locally define species in the mechanism as fast or slow on the basis of their total production and loss rates, and we solve the coupled kinetic system only for the fast species assembled in a submechanism of the full mechanism. To avoid computational overhead, we first partition the species from the full mechanism into 13 blocks, using a machine learning approach that analyzes the chemical linkages between species and their correlated presence as fast or slow in the global model domain. Building on these blocks, we then preselect 20 submechanisms, as defined by unique assemblages of the species blocks, and then pick locally and on the fly which submechanism to use in the model based on local chemical conditions. In each submechanism, we isolate slow species and slow reactions from the coupled system of fast species to be solved. Because many species in the full mechanism are important only in source regions, we find that we can reduce the effective size of the mechanism by 70 % globally without sacrificing complexity where/when it is needed. The computational cost of the chemical integration decreases by 50 % with relative biases smaller than 2 % for important species over 8-year simulations. Changes to the full mechanism including the addition of new species can be accommodated by adding these species to the relevant blocks without having to reconstruct the suite of submechanisms.
The dengue virus affects millions of people every year worldwide, causing large epidemic outbreaks that disrupt people’s lives and severely strain healthcare systems. In the absence of a reliable vaccine against dengue or an effective treatment to manage the illness in humans, most efforts to combat dengue infections have focused on preventing its vectors, mainly the Aedes aegypti mosquito, from flourishing across the world. These mosquito-control strategies need reliable disease activity surveillance systems to be deployed. Despite significant efforts to estimate dengue incidence using a variety of data sources and methods, little work has been done to understand the relative contribution of the different data sources to improved prediction. Additionally, scholarship on the topic had initially focused on prediction systems at the national- and state-levels, and much remains to be done at the finer spatial resolutions at which health policy interventions often occur. We develop a methodological framework to assess and compare dengue incidence estimates at the city level, and evaluate the performance of a collection of models on 20 different cities in Brazil. The data sources we use towards this end are weekly incidence counts from prior years (seasonal autoregressive terms), weekly-aggregated weather variables, and real-time internet search data. We find that both random forest-based models and LASSO regression-based models effectively leverage these multiple data sources to produce accurate predictions, and that while the performance between them is comparable on average, the former method produces fewer extreme outliers, and can thus be considered more robust. For real-time predictions that assume long delays (6–8 weeks) in the availability of epidemiological data, we find that real-time internet search data are the strongest predictors of dengue incidence, whereas for predictions that assume short delays (1–3 weeks), in which the error rate is halved (as measured by relative RMSE), short-term and seasonal autocorrelation are the dominant predictors. Despite the difficulties inherent to city-level prediction, our framework achieves meaningful and actionable estimates across cities with different demographic, geographic and epidemic characteristics.
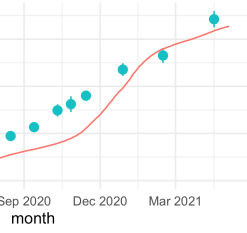
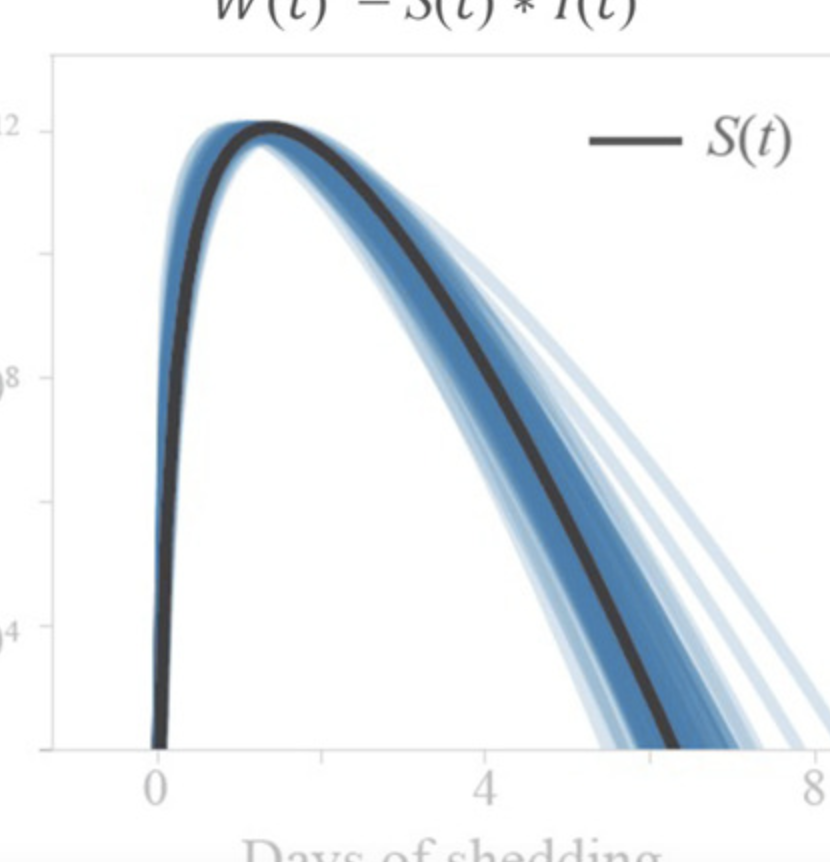
SARS-CoV-2 RNA concentrations in wastewater foreshadow dynamics and clinical presentation of new COVID-19 cases Fuqing Wu, Amy Xiao, Jianbo Zhang, Katya Moniz, Noriko Endo, Federica Armas, Richard Bonneau, Megan A Brown, Mary Bushman, Peter R Chai, Claire Duvallet, Timothy B Erickson, Katelyn Foppe, Newsha Ghaeli, Xiaoqiong Gu, William P Hanage, Katherine H Huang, Wei Lin Lee, Mariana Matus, Kyle A McElroy, Jonathan Nagler, Steven F Rhode, Mauricio Santillana, Joshua A Tucker, Stefan Wuertz, Shijie Zhao, Janelle Thompson, Eric J Alm Science of The Total Environment 805, 1501211452022
Abstract
Current estimates of COVID-19 prevalence are largely based on symptomatic, clinically diagnosed cases. The existence of a large number of undiagnosed infections hampers population-wide investigation of viral circulation. Here, we quantify the SARS-CoV-2 concentration and track its dynamics in wastewater at a major urban wastewater treatment facility in Massachusetts, between early January and May 2020. SARS-CoV-2 was first detected in wastewater on March 3. SARS-CoV-2 RNA concentrations in wastewater correlated with clinically diagnosed new COVID-19 cases, with the trends appearing 4–10 days earlier in wastewater than in clinical data. We inferred viral shedding dynamics by modeling wastewater viral load as a convolution of back-dated new clinical cases with the average population-level viral shedding function. The inferred viral shedding function showed an early peak, likely before symptom onset and clinical diagnosis, consistent with emerging clinical and experimental evidence. This finding suggests that SARS-CoV-2 concentrations in wastewater may be primarily driven by viral shedding early in infection. This work shows that longitudinal wastewater analysis can be used to identify trends in disease transmission in advance of clinical case reporting, and infer early viral shedding dynamics for newly infected individuals, which are difficult to capture in clinical investigations.
ImportanceMisinformation about COVID-19 vaccination may contribute substantially to vaccine hesitancy and resistance. ObjectiveTo determine if depressive symptoms are associated with greater likelihood of believing vaccine-related misinformation. Design, Setting, and ParticipantsThis survey study analyzed responses from 2 waves of a 50-state nonprobability internet survey conducted between May and July 2021, in which depressive symptoms were measured using the Patient Health Questionnaire 9-item (PHQ-9). Survey respondents were aged 18 and older. Population-reweighted multiple logistic regression was used to examine the association between moderate or greater depressive symptoms and endorsement of at least 1 item of vaccine misinformation, adjusted for sociodemographic features. The association between depressive symptoms in May and June, and new support for misinformation in the following wave was also examined. ExposuresDepressive symptoms. Main Outcomes and MeasuresThe main outcome was endorsing any of 4 common vaccine-related statements of misinformation. ResultsAmong 15 464 survey respondents (9834 [63.6%] women and 5630 [36.4%] men; 722 Asian respondents [4.7%], 1494 Black respondents [9.7%], 1015 Hispanic respondents [6.6%], and 11 863 White respondents [76.7%]; mean [SD] age, 47.9 [17.5] years), 4164 respondents (26.9%) identified moderate or greater depressive symptoms on the PHQ-9, and 2964 respondents (19.2%) endorsed at least 1 vaccine-related statement of misinformation. Presence of depression was associated with increased likelihood of endorsing misinformation (crude odds ratio [OR], 2.33; 95% CI, 2.09-2.61; adjusted OR, 2.15; 95% CI, 1.91-2.43). Respondents endorsing at least 1 misinformation item were significantly less likely to be vaccinated (crude OR, 0.40; 95% CI, 0.36-0.45; adjusted OR, 0.45; 95% CI, 0.40-0.51) and more likely to report vaccine resistance (crude OR, 2.54; 95% CI, 2.21-2.91; adjusted OR, 2.68; 95% CI, 2.89-3.13). Among 2809 respondents who answered a subsequent survey in July, presence of depression in the first survey was associated with greater likelihood of endorsing more misinformation compared with the prior survey (crude OR, 1.98; 95% CI, 1.42-2.75; adjusted OR, 1.63; 95% CI, 1.14-2.33). Conclusions and RelevanceThis survey study found that individuals with moderate or greater depressive symptoms were more likely to endorse vaccine-related misinformation, cross-sectionally and at a subsequent survey wave. While this study design cannot address causation, the association between depression and spread and impact of misinformation merits further investigation.
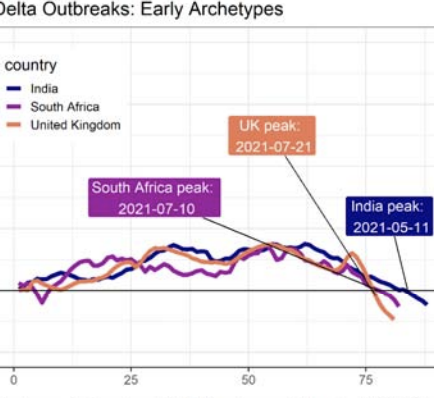
Characterizing the dynamics of epidemic trajectories is critical to understanding the potential impacts of emerging outbreaks and to designing appropriate mitigation strategies. As the COVID-19 pandemic evolves, however, the emergence of SARS-CoV-2 variants of concern has complicated our ability to assess in real-time the potential effects of imminent outbreaks, such as those presently caused by the Omicron variant. Here, we report that SARS-CoV-2 outbreaks across regions exhibit strain-specific times from onset to peak, specifically for Delta and Omicron variants. Our findings may facilitate real-time identification of peak medical demand and may help fine-tune ongoing and future outbreak mitigation deployment efforts.
Using general messages to persuade on a politicized scientific issue Jon Green, James N Druckman, Matthew A Baum, David Lazer, Katherine Ognyanova, Matthew Simonson, Jennifer Lin, Mauricio Santillana, Roy H Perlis British Journal of Political Science, 1-9. doi:10.1017/S0007123422000424
Abstract
Politics and science have become increasingly intertwined. Salient scientific issues such as climate change, evolution, and stem cell research become politicized, pitting partisans against one another. This creates a challenge of how to effectively communicate on such issues. Recent work emphasizes the need for tailored messages to specific groups. Here, we focus on whether generalized messages also can matter. We do so in the context of a highly polarized issue – extreme COVID-19 vaccine resistance. The results show that science-based, moral frame, and social norm messages move behavioral intentions, and do so by the same amount across the population (i.e., homogenous effects). Counter to common portrayals, the politicization of science does not preclude using broad messages that resonate with the entire population.