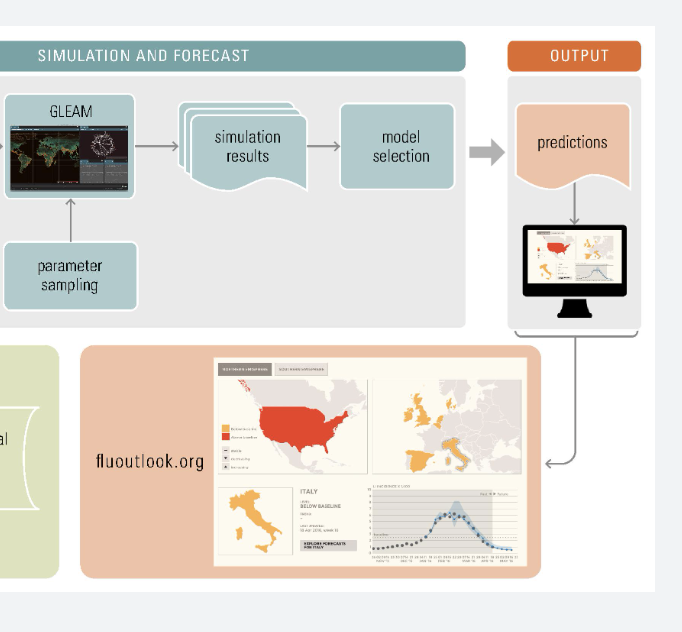
BackgroundOver 400,000 people across the Americas are thought to have been infected with Zika virus as a consequence of the 2015–2016 Latin American outbreak. Official government-led case count data in Latin America are typically delayed by several weeks, making it difficult to track the disease in a timely manner. Thus, timely disease tracking systems are needed to design and assess interventions to mitigate disease transmission. Methodology/Principal FindingsWe combined information from Zika-related Google searches, Twitter microblogs, and the HealthMap digital surveillance system with historical Zika suspected case counts to track and predict estimates of suspected weekly Zika cases during the 2015–2016 Latin American outbreak, up to three weeks ahead of the publication of official case data. We evaluated the predictive power of these data and used a dynamic multivariable approach to retrospectively produce predictions of weekly suspected cases for five countries: Colombia, El Salvador, Honduras, Venezuela, and Martinique. Models that combined Google (and Twitter data where available) with autoregressive information showed the best out-of-sample predictive accuracy for 1-week ahead predictions, whereas models that used only Google and Twitter typically performed best for 2- and 3-week ahead predictions. SignificanceGiven the significant delay in the release of official government-reported Zika case counts, we show that these Internet-based data streams can be used as timely and complementary ways to assess the dynamics of the outbreak.
Background:Influenza outbreaks affect millions of people every year and its surveillance is usually carried out in developed countries through a network of sentinel doctors who report the weekly number of Influenza-like Illness cases observed among the visited patients. Monitoring and forecasting the evolution of these outbreaks supports decision makers in designing effective interventions and allocating resources to mitigate their impact. Objective:Describe the existing participatory surveillance approaches that have been used for modeling and forecasting of the seasonal influenza epidemic, and how they can help strengthen real-time epidemic science and provide a more rigorous understanding of epidemic conditions. Methods:We describe three different participatory surveillance systems, WISDM (Widely Internet Sourced Distributed Monitoring), Influenzanet and Flu Near You (FNY), and show how modeling and simulation can be or has been combined with participatory disease surveillance to: i) measure the non-response bias in a participatory surveillance sample using WISDM; and ii) nowcast and forecast influenza activity in different parts of the world (using Influenzanet and Flu Near You). Results:WISDM-based results measure the participatory and sample bias for three epidemic metrics i.e. attack rate, peak infection rate, and time-to-peak, and find the participatory bias to be the largest component of the total bias. The Influenzanet platform shows that digital participatory surveillance data combined with a realistic data-driven epidemiological model can provide both short-term and long-term forecasts of epidemic intensities, and the ground truth data lie within the 95 percent confidence intervals for most weeks. The statistical accuracy of the ensemble forecasts increase as the season progresses. The Flu Near You platform shows that participatory surveillance data provide accurate short-term flu activity forecasts and influenza activity predictions. The correlation of the HealthMap Flu Trends estimates with the observed CDC ILI rates is 0.99 for 2013-2015. Additional data sources lead to an error reduction of about 40% when compared to the estimates of the model that only incorporates CDC historical information. Conclusions:While the advantages of participatory surveillance, compared to traditional surveillance, include its timeliness, lower costs, and broader reach, it is limited by a lack of control over the characteristics of the population sample. Modeling and simulation can help overcome this limitation as well as provide real-time and long-term forecasting of influenza activity in data-poor parts of the world.
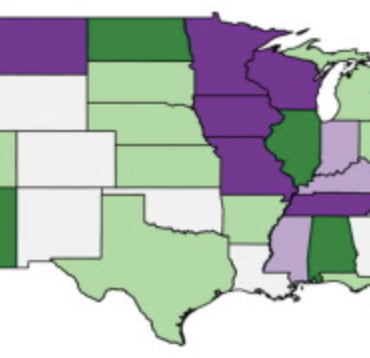
United States kindergarten measles-mumps-rubella (MMR) vaccination rates are typically reported at the state level by the Centers for Disease Control and Prevention (CDC). The lack of local MMR data prevents identification of areas with low vaccination rates that would be vulnerable to the spread of disease. We collected county-level vaccination rates for the 2014-2015 school year with the objective of identifying these regions. We requested county-level kindergarten vaccination data from state health departments, and mapped these data to visualize geographic patterns in achievement of the 95% MMR vaccination target. We aggregated the county-level data to the state level for comparison against CDC state estimates. We also analyzed the relationship of MMR vaccination level with county-level and state-level poverty (using U.S. census data), using both a national mixed model with state as a random effect, and individual linear regression models by state. We received county vaccination data from 43 states. The median kindergarten MMR vaccination rate was 96.0% (IQR 89-98) across all counties, however, we estimated that 48.4% of the represented counties had vaccination rates below 95%. Our state estimates closely reflected CDC values. Nationally, every 10% increase in under-18 county poverty was associated with a 0.24% increase in MMR vaccination rates (95% CI: -0.07%; 0.54%), but the direction of this relationship varied by state. We found that county data can reveal vaccination trends that are unobservable from state-level data, but we also discovered that the current availability of county-level data is inadequate. Our findings can be used by state health departments to identify target areas for vaccination programs.
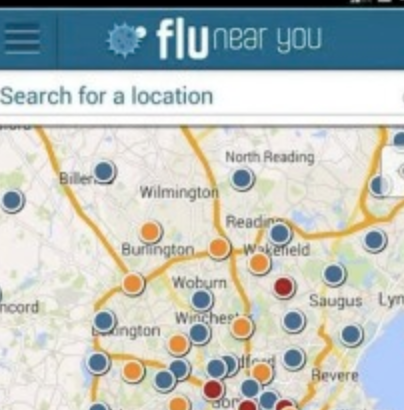
Background:Flu Near You (FNY) is an Internet-based participatory surveillance system in the United States and Canada that allows volunteers to report influenza-like symptoms using a brief weekly symptom report. Objective:Our objective was to evaluate the representativeness of the FNY population compared with the general population of the United States, explore the demographic and behavioral characteristics associated with FNY’s high-participation users, and summarize results from a user survey of a cohort of FNY participants. Methods:We compared (1) the representativeness of sex and age groups of FNY participants during the 2014-2015 flu season versus the general US population and (2) the distribution of Human Development Index (HDI) scores of FNY participants versus that of the general US population. We analyzed associations between demographic and behavioral factors and the level of participant follow-up (ie, high vs low). Finally, descriptive statistics of responses from FNY’s 2015 and 2016 end-of-season user surveys were calculated. Results:During the 2014-2015 influenza season, 47,234 unique participants had at least one FNY symptom report that was either self-reported (users) or submitted on their behalf (household members). The proportion of female FNY participants was significantly higher than that of the general US population (n=28,906, 61.2% vs 51.1%, P<.001). Although each age group was represented in the FNY population, the age distribution was significantly different from that of the US population (P<.001). Compared with the US population, FNY had a greater proportion of individuals with HDI >5.0, signaling that the FNY user distribution was more affluent and educated than the US population baseline. We found that high-participation use (ie, higher participation in follow-up symptom reports) was associated with sex (females were 25% less likely than men to be high-participation users), higher HDI, not reporting an influenza-like illness at the first symptom report, older age, and reporting for household members (all differences between high- and low-participation users P<.001). Approximately 10% of FNY users completed an additional survey at the end of the flu season that assessed detailed user characteristics (3217/33,324 in 2015; 4850/44,313 in 2016). Of these users, most identified as being either retired or employed in the health, education, and social services sectors and indicated that they achieved a bachelor’s degree or higher. Conclusions:The representativeness of the FNY population and characteristics of its high-participation users are consistent with what has been observed in other Internet-based influenza surveillance systems. With targeted recruitment of underrepresented populations, FNY may improve as a complementary system to timely tracking of flu activity, especially in populations that do not seek medical attention and in areas with poor official surveillance data.
Dengue is a mosquito-borne disease that threatens more than half of the world's population. Despite being endemic to over 100 countries, government-led efforts and mechanisms to timely identify and track the emergence of new infections are still lacking in many affected areas. Multiple methodologies that leverage the use of Internet-based data sources have been proposed as a way to complement dengue surveillance efforts. Among these, the trends in dengue-related Google searches have been shown to correlate with dengue activity. We extend a methodological framework, initially proposed and validated for flu surveillance, to produce near real-time estimates of dengue cases in five countries/regions: Mexico, Brazil, Thailand, Singapore and Taiwan. Our result shows that our modeling framework can be used to improve the tracking of dengue activity in multiple locations around the world.
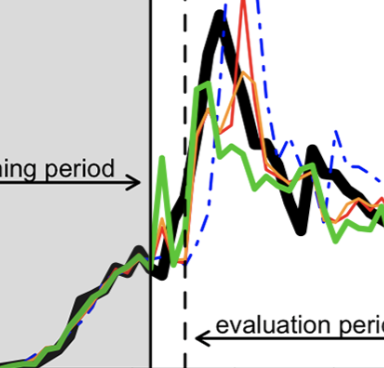
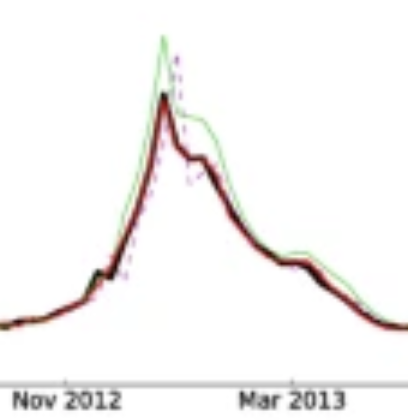
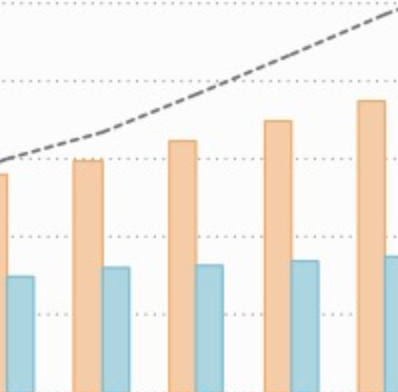
BackgroundAccurate influenza activity forecasting helps public health officials prepare and allocate resources for unusual influenza activity. Traditional flu surveillance systems, such as the Centers for Disease Control and Prevention’s (CDC) influenza-like illnesses reports, lag behind real-time by one to 2 weeks, whereas information contained in cloud-based electronic health records (EHR) and in Internet users’ search activity is typically available in near real-time. We present a method that combines the information from these two data sources with historical flu activity to produce national flu forecasts for the United States up to 4 weeks ahead of the publication of CDC’s flu reports. MethodsWe extend a method originally designed to track flu using Google searches, named ARGO, to combine information from EHR and Internet searches with historical flu activities. Our regularized multivariate regression model dynamically selects the most appropriate variables for flu prediction every week. The model is assessed for the flu seasons within the time period 2013–2016 using multiple metrics including root mean squared error (RMSE). ResultsOur method reduces the RMSE of the publicly available alternative (Healthmap flutrends) method by 33, 20, 17 and 21%, for the four time horizons: real-time, one, two, and 3 weeks ahead, respectively. Such accuracy improvements are statistically significant at the 5% level. Our real-time estimates correctly identified the peak timing and magnitude of the studied flu seasons. ConclusionsOur method significantly reduces the prediction error when compared to historical publicly available Internet-based prediction systems, demonstrating that: (1) the method to combine data sources is as important as data quality; (2) effectively extracting information from a cloud-based EHR and Internet search activity leads to accurate forecast of flu.
With the rapid expansion of Internet access worldwide, large portions of the general public now seek and access health information through Internet search engines. As a consequence, the past decade has seen the emergence of multiple research efforts aimed at understanding how Internet users' behavior on search engines may be used to map changes in population-wide disease incidence and transmission in near real time. One of the earliest efforts, performed by a team at Google, led to the creation of Google Flu Trends (GFT), a biosurveillance system that used the volume of selected Google search terms to estimate flu activity in the United States a week ahead of the publication of government-led flu reports [1]. GFT was launched in 2008 and displayed real-time updates of flu activity for the United States from that point on. Soon after, GFT predictive methodology was extended to provide flu estimates for multiple countries around the globe. Methodology/Principal FindingsWe combined information from Zika-related Google searches, Twitter microblogs, and the HealthMap digital surveillance system with historical Zika suspected case counts to track and predict estimates of suspected weekly Zika cases during the 2015–2016 Latin American outbreak, up to three weeks ahead of the publication of official case data. We evaluated the predictive power of these data and used a dynamic multivariable approach to retrospectively produce predictions of weekly suspected cases for five countries: Colombia, El Salvador, Honduras, Venezuela, and Martinique. Models that combined Google (and Twitter data where available) with autoregressive information showed the best out-of-sample predictive accuracy for 1-week ahead predictions, whereas models that used only Google and Twitter typically performed best for 2- and 3-week ahead predictions. SignificanceGiven the significant delay in the release of official government-reported Zika case counts, we show that these Internet-based data streams can be used as timely and complementary ways to assess the dynamics of the outbreak.
Dengue viruses, which infect millions of people per year worldwide, cause large epidemics that strain healthcare systems. Despite diverse efforts to develop forecasting tools including autoregressive time series, climate-driven statistical and mechanistic biological models, little work has been done to understand the contribution of different components to improved prediction. We developed a framework to assess and compare dengue forecasts produced from different types of models and evaluated the performance of seasonal autoregressive models with and without climate variables for forecasting dengue incidence in Mexico. Climate data did not significantly improve the predictive power of seasonal autoregressive models. Short-term and seasonal autocorrelation were key to improving short-term and long-term forecasts, respectively. Seasonal autoregressive models captured a substantial amount of dengue variability, but better models are needed to improve dengue forecasting. This framework contributes to the sparse literature of infectious disease prediction model evaluation, using state-of-the-art validation techniques such as out-of-sample testing and comparison to an appropriate reference model.
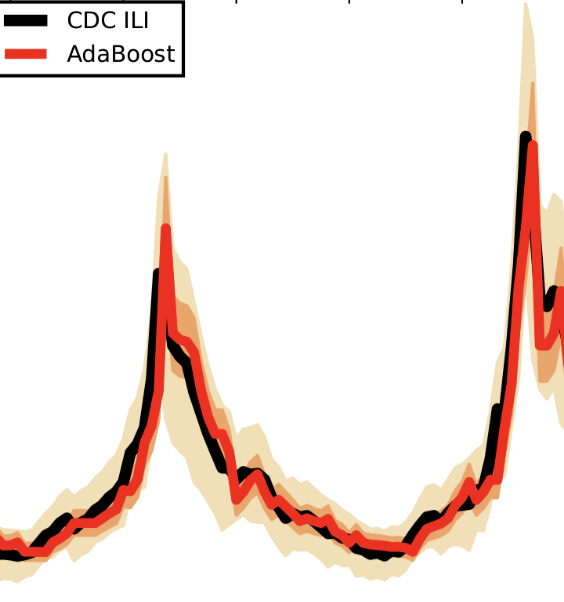
Accurate real-time monitoring systems of influenza outbreaks help public health officials make informed decisions that may help save lives. We show that information extracted from cloud-based electronic health records databases, in combination with machine learning techniques and historical epidemiological information, have the potential to accurately and reliably provide near real-time regional estimates of flu outbreaks in the United States.
Background: Approximately 40 countries in Central and South America have experienced local vector-born transmission of Zika virus, resulting in nearly 300,000 total reported cases of Zika virus disease to date. Of the cases that have sought care thus far in the region, more than 70,000 have been reported out of Colombia. Objective: In this paper, we use nontraditional digital disease surveillance data via HealthMap and Google Trends to develop near real-time estimates for the basic (R) and observed (Robs) reproductive numbers associated with Zika virus disease in Colombia. We then validate our results against traditional health care-based disease surveillance data. Methods: Cumulative reported case counts of Zika virus disease in Colombia were acquired via the HealthMap digital disease surveillance system. Linear smoothing was conducted to adjust the shape of the HealthMap cumulative case curve using Google search data. Traditional surveillance data on Zika virus disease were obtained from weekly Instituto Nacional de Salud (INS) epidemiological bulletin publications. The Incidence Decay and Exponential Adjustment (IDEA) model was used to estimate R0 and Robs for both data sources. Results: Using the digital (smoothed HealthMap) data, we estimated a mean R0 of 2.56 (range 1.42-3.83) and a mean Robs of 1.80 (range 1.42-2.30). The traditional (INS) data yielded a mean R0 of 4.82 (range 2.34-8.32) and a mean Robs of 2.34 (range 1.60-3.31).
We present upper bounds for the numerical errors introduced when using operator splitting methods to integrate transport and non-linear chemistry processes in global chemical transport models (CTM). We show that (a) operator splitting strategies that evaluate the stiff non-linear chemistry operator at the end of the time step are more accurate, and (b) the results of numerical simulations that use different operator splitting strategies differ by at most 10%, in a prototype one-dimensional non-linear chemistry–transport model. We find similar upper bounds in operator splitting numerical errors in global CTM simulations.
In this commentary, we consider the relationship between early outbreak changes in the observed reproductive number of Ebola in West Africa and various media reported interventions and aggravating events. We find that media reports of interventions that provided education, minimized contact, or strengthened healthcare were typically followed by sustained transmission reductions in both Sierra Leone and Liberia. Meanwhile, media reports of aggravating events generally preceded temporary transmission increases in both countries. Given these preliminary findings, we conclude that media reported events could potentially be incorporated into future epidemic modeling efforts to improve mid-outbreak case projections.
Objectives. We summarized Flu Near You (FNY) data from the 2012–2013 and 2013–2014 influenza seasons in the United States. Methods. FNY collects limited demographic characteristic information upon registration, and prompts users each Monday to report symptoms of influenza-like illness (ILI) experienced during the previous week. We calculated the descriptive statistics and rates of ILI for the 2012–2013 and 2013–2014 seasons. We compared raw and noise-filtered ILI rates with ILI rates from the Centers for Disease Control and Prevention ILINet surveillance system. Results. More than 61 000 participants submitted at least 1 report during the 2012–2013 season, totaling 327 773 reports. Nearly 40 000 participants submitted at least 1 report during the 2013–2014 season, totaling 336 933 reports. Rates of ILI as reported by FNY tracked closely with ILINet in both timing and magnitude. Conclusions. With increased participation, FNY has the potential to serve as a viable complement to existing outpatient, hospital-based, and laboratory surveillance systems. Although many established systems have the benefits of specificity and credibility, participatory systems offer advantages in the areas of speed, sensitivity, and scalability.
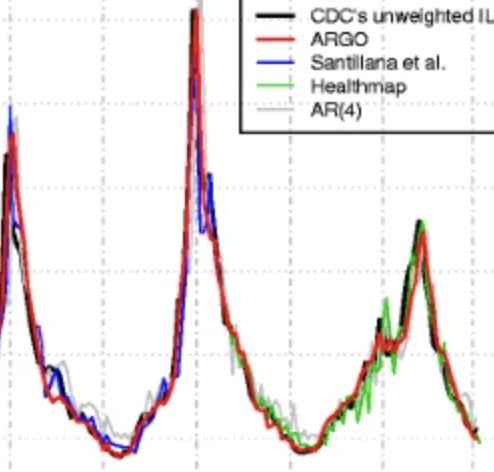
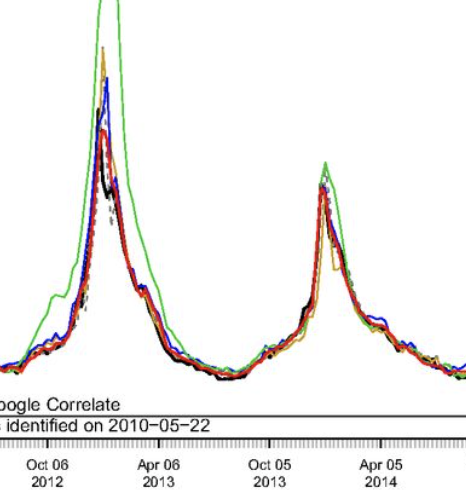
Accurate real-time tracking of influenza outbreaks helps public health officials make timely and meaningful decisions that could save lives. We propose an influenza tracking model, ARGO (AutoRegression with GOogle search data), that uses publicly available online search data. In addition to having a rigorous statistical foundation, ARGO outperforms all previously available Google-search–based tracking models, including the latest version of Google Flu Trends, even though it uses only low-quality search data as input from publicly available Google Trends and Google Correlate websites. ARGO not only incorporates the seasonality in influenza epidemics but also captures changes in people’s online search behavior over time. ARGO is also flexible, self-correcting, robust, and scalable, making it a potentially powerful tool that can be used for real-time tracking of other social events at multiple temporal and spatial resolutions.
We present a machine learning-based methodology capable of providing real-time (“nowcast”) and forecast estimates of influenza activity in the US by leveraging data from multiple data sources including: Google searches, Twitter microblogs, nearly real-time hospital visit records, and data from a participatory surveillance system. Our main contribution consists of combining multiple influenza-like illnesses (ILI) activity estimates, generated independently with each data source, into a single prediction of ILI utilizing machine learning ensemble approaches. Our methodology exploits the information in each data source and produces accurate weekly ILI predictions for up to four weeks ahead of the release of CDC’s ILI reports. We evaluate the predictive ability of our ensemble approach during the 2013–2014 (retrospective) and 2014–2015 (live) flu seasons for each of the four weekly time horizons. Our ensemble approach demonstrates several advantages: (1) our ensemble method’s predictions outperform every prediction using each data source independently, (2) our methodology can produce predictions one week ahead of GFT’s real-time estimates with comparable accuracy, and (3) our two and three week forecast estimates have comparable accuracy to real-time predictions using an autoregressive model. Moreover, our results show that considerable insight is gained from incorporating disparate data streams, in the form of social media and crowd sourced data, into influenza predictions in all time horizons.